ヒストグラムに確率分布の曲線を重ねる方法
Rで統計分析をする際、得られたデータをヒストグラムにしてデータの分布を確認し、
その上に正規分布などの確率分布の曲線を重ねて表示したいことがよくあります。
今回はその方法について解説します。
まず、例えば日本人の成人男性を30人ランダムにサンプリング(抽出)したところ、各男性の身長が以下のように得られたとします。
> X
[1] 163.30 168.66 173.07 161.78 172.57 171.24 171.68 179.93 161.25 181.14
[11] 165.04 161.95 165.27 173.02 172.22 168.54 163.38 165.81 180.79 172.60
[21] 166.37 163.46 169.37 157.67 167.12 165.07 180.28 179.10 170.42 161.91
[1] 163.30 168.66 173.07 161.78 172.57 171.24 171.68 179.93 161.25 181.14
[11] 165.04 161.95 165.27 173.02 172.22 168.54 163.38 165.81 180.79 172.60
[21] 166.37 163.46 169.37 157.67 167.12 165.07 180.28 179.10 170.42 161.91
このデータをヒストグラムにして分布を調べてみましょう。
# 日本語フォントの指定
par(family = "HiraKakuProN-W3")
# ヒストグラム作成
hist(X,
main="30人の日本人成人男性の身長",
xlab="身長",
ylab="",
prob=T)
以下のようなヒストグラムが描けます。
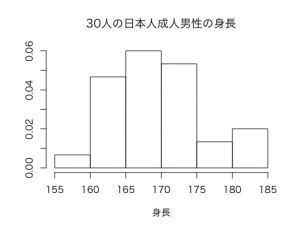
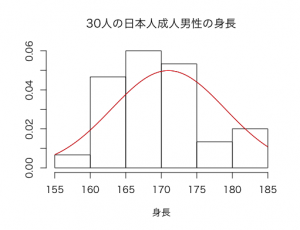
日本人の成人男性の身長はだいたい平均値171cm、分散64、標準偏差8の正規分布に近い分布をしていますので、この正規分布を重ねてみます。
curve()関数で、()内にdnorm(x,171,8)を指定することにより、正規分布の確率密度関数を描くことができます。
これを、ヒストグラムに重ねたいのでadd=TRUEを追加します。
curve(dnorm(x,171,8),
add=TRUE,
col="red")
これにより、以下のように正規分布の確率密度関数の曲線を重ねることができました。
なお、この30人の身長のデータは以下のコードで同じものを発生させることができます。
# 毎回同じ乱数を発生させる set.seed(3) #平均171標準偏差8の正規分布から30個のデータを抽出 X=rnorm(30,171,8) # 少数第三位を四捨五入 X=round(X,digits = 2)

