統計学やデータ分析において「データを可視化」することが非常に重要です。
例えば回帰分析は多くの場合、説明変数と応答変数の間の「直線的」な関係を
モデリングしますが、
散布図を用いて変数の関係を可視化することで、変数の間に
「直線的な関係があるのか?」それとも
「曲線的な関係があるのか?」
といったことを視覚的に理解できます。
今回は、Pythonを用いて散布図を描く方法をご紹介します。
以下のようにまずは必要なライブラリをインポートしましょう。
import pandas as pd # データフレームを作成するライブラリ import numpy as np #数値計算を行うためのライブラリ from sklearn.datasets import load_boston #ボストンの住宅価格データをインポート import matplotlib.pyplot as plt #散布図を描くライブラリ
sklearn.datasetsを用いて、ボストンの住宅価格のデータを利用してみます。
なお、データと各変数の説明は(英語ですが)以下のページに載せられています。
http://scikit-learn.org/stable/datasets/index.html
まずは、以下のようにデータをデータフレームに収めます。
mydata = pd.DataFrame(load_boston().data, columns=load_boston().feature_names)
大きめのデータセットなので、初めの5行を見てみましょう。
>>>mydata.head()
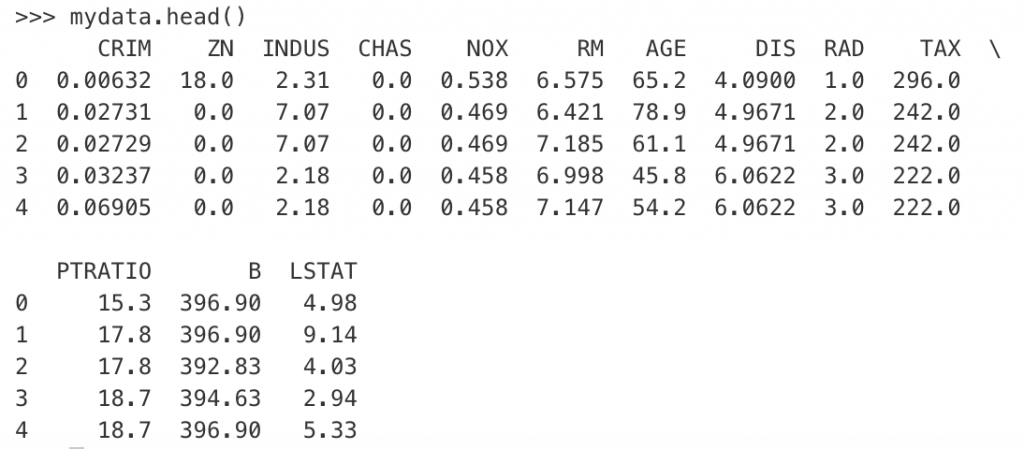
なおデータフレームの大きさはshapeコマンドで確認できます。
>>> mydata.shape
(506, 13)
これにより、全部で横の行が506行、縦列が13列あることが分かります。
データの内容を把握するために、どんな変数があるのか一通り確認しましょう。
>>> mydata.columns.values.tolist()
[‘CRIM’,
‘ZN’,
‘INDUS’,
‘CHAS’,
‘NOX’,
‘RM’,
‘AGE’,
‘DIS’,
‘RAD’,
‘TAX’,
‘PTRATIO’,
‘B’,
‘LSTAT’]
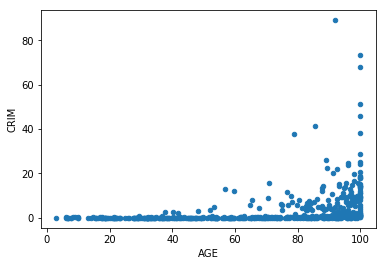
それでは早速、散布図を描いてみます。
Pandasライブラリを利用して変数AGEとCRIMEの関係を見てみましょう。
# pandasライブラリを利用して散布図を描く mydata.plot.scatter(x='AGE', y='CRIM')
次にmatplotlib.pyplotライブラリを利用して、
データフレームから変数の列を抜き出して散布図を描いてみます。
# matplotlib.pyplotライブラリを利用して散布図を描く
# データフレームから変数AGEとCRIMを抜き出す。
x = mydata.loc[:,'AGE']
y = mydata.loc[:,'CRIM']
# 散布図を描く
plt.scatter(x, y)
# X軸、Y軸のラベルをつける。
plt.xlabel("AGE proportion of owner-occupied units built prior to 1940")
plt.ylabel("CRIM per capita crime rate by town")
# 図にタイトルをつける。
plt.title("Age vs Crime", loc='center')
plt.show()
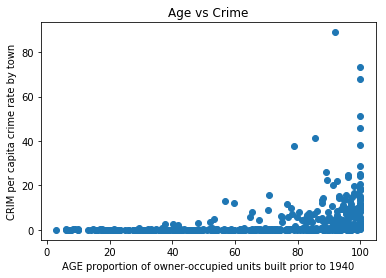
このようにラベルとタイトルがついた散布図を作成することができました。
※この記事を書くのに以下のページを参照しました。
pandasライブラリ
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.scatter.html
matplotlib.pyplotライブラリ
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.title.html

